Were do we come from?
Digital compositing has always been evolving. Creating impossible realities has been a challenge even before Méliès and Chomón. Although the technology has changed radically from analogical to digital means, the basics still remain the same: overlapping different elements as if they were part of one single shot. Making the composition believable can sometimes be tricky. In the last years, many tools have been developed that artists can use to achieve impossible goals.
Rotoscoping, keying and grading still remain as the key tools of every compositor. 3D Tracking is perhaps the most recent tool that has changed the way visual effects are done, both in 2D and 3D. What tools lay ahead? Are there any revolutionary items just around the corner? What is the future of digital compositing?

Where are we heading to?
What I will try on this article is to make predictions. Some of these will occur and some may not, time will tell. I will be missing many important bits along the article. Real time 3D environment integration, great new capabilities of the render engines, a network which shares the tools people develop for free… There are many factors which make compositing evolve at a very high speed. But I think there are a few main points that will be crucial for the future’s compositing workflow.
Getting procedural
Speed and efficiency are the current main goals of research and development. Moore’s law states how transistor’s capabilities exponentially increase over time. This means every year, programmers will be able to develop more powerful software, using both CPU and GPU capabilities. More speed also means that more complex algorithms will automatize many tasks which are currently being done by artists. This involves tracking, rotoscoping and many other tedious tasks which are very time consuming at the moment. A smart compositing software will be a matter of fact in just a few years in the future. My guess is that it will probably be AI, deep learning related. I am not even going to talk about quantum computers and all of the possibilities that they bring, but be sure that this is going to be a big revolution, specially if you are a big studio and you can afford having one of those.
The mythical node which only shows itself on dreams.
Real-time render
Five years ago, this was unimaginable even for the fastest computers, but ultra fast renders are already between us, and we can see the proof of that on the latest video games graphics achievements. We are starting to see some of this advance on compositing programs in plugins such as Element 3D, which has proofed to be a revolutionary tool for motion design artists. This technology is very recent, but with a few more years of research, it is almost assured that it will be a giant leap for the VFX industry.
The idea behind this feature is simple, removing the intermediate step between the 3D department and the compositing department. This will allow shots to jump back and forth if the director wants to make any changes without having to re-render the entire sequence. Of course, this type of GPU workflow will not be used by the large industry for, let’s say, 20 years at least, until it gets to the same level of photorealism as raytracing. But it is already taking place in the tiny but constantly adapting, small industry.
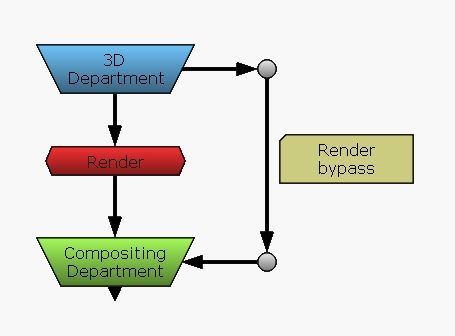
Bypassing the render process adds a lot of flexibility to the workflow.
New technologies
Everything we have said so far is about improving what already exist. More speed, more power, more resolution, more speed… But is there going to be anything new we don’t know so far? Well, we do have some hints of what will we probably start using in the following years.
Depth cameras and depth compositing
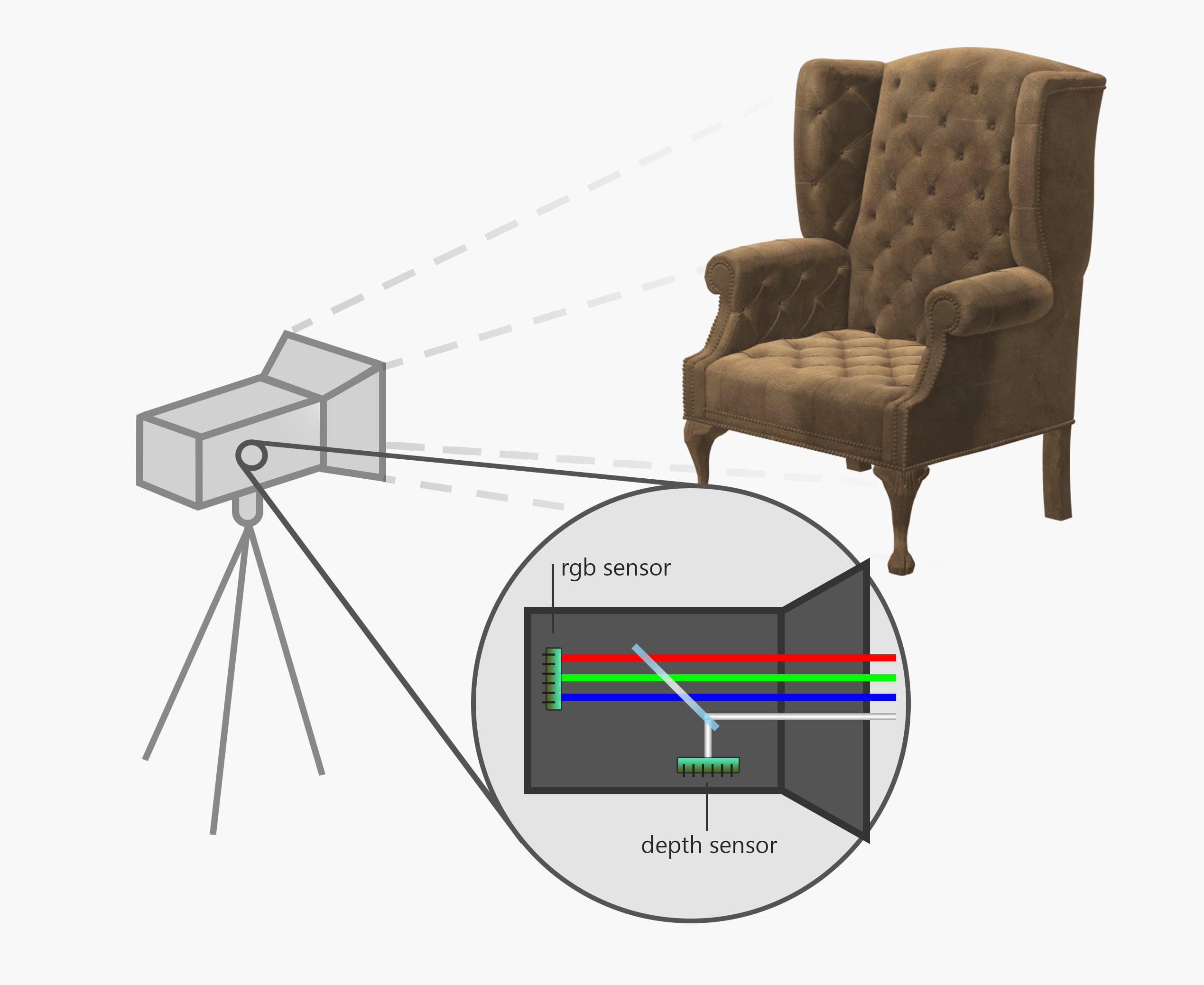
Well, I lied, this is actually not a “new”, technology, actually it has been around for a couple of years. But it has never been used as a compositing tool. What is this all about? All cameras capture image with the rgb channels. The idea is to add a fourth channel to the image, channel Z, with stands for depth. How this channel is captured depends on the technology, but it usually involves an infrared or light field sensor. It is not clear either if the video will be exported as a new rgbz format (which is not supported by compositing software such as Nuke yet), or as a separated shot, being the second chance more probable.

First, there was the luminance matte, then we invented the difference and the chroma matte. The next step: the depth matte. Why is this matte useful? I have already covered this topic, but imagine to be able to extract a silhouette from an urban shot without any rotoscopy or chroma keying, imagine to be able to relight a shot for dramatic effect without having to re-built the scene in 3D… Add to all this features stereo conversion, the ability to add depth of field in postproduction, a great control over volumetric effects such as fog… There is a huge amount of possibilities to be discovered with the depth compositing. And of course, you can add to the list the 3D scan capabilities which you can already use.
When I talked about the real time render I mentioned how this technique has started spreading at the smaller industry and how it is difficult that it will leak into the big film industry. With this technology we have the opposite case. Although current cameras are quite affordable, this technology will only be functional at very high resolutions with very high precision cameras which haven’t been invented yet. Do not be surprised if the ILM or the MPC get one of those before you. The process will be very similar to mocap, starting only in some movies and then spreading to the hole industry, only that this will happen much faster.
Each Z pixel corresponds to 4 or 8 rgb pixels
Nowadays, of course, there’s plenty of limitations. First of all, the infrared lights are currently limited to interior scenes, because the direct sunlight will interfere with the camera sensors. Also, multiple cameras would need to be adjusted very precisely if we do not want them to interfere between each other. There’s also the range problem, where only objects at a certain distance are displayed properly. All of this issues can and will be solved with further development. The second main problem is resolution. The infrared sensor has a very low resolution, which makes sense once you understand how this technology works.
A solution to this problem could be using a simple algorithm to filter the z pixels using the rgb data. This process would split every z pixel into 4 or 8 pieces depending on the resolution. Then, using the information captured by the colour sensor, those pixels would be modified in order to fit the silhouettes on the rgb channels. This increases the accuracy of the depth map. This would also make compositing easier and avoid lots of artifacts, as it would make both resolutions match.
“Any sufficiently advanced technology is indistinguishable from magic.”
Arthur C. Clarke